
Reliability by DevOps
Software is a peculiar industry. Famously fad-prone and in a constant oscillatory motion between styles and approaches—what is cool today was the enemy yesterday—today we witness a rapid proliferation of service-based architectures (SBA) that come to save us from the evil monoliths that ruled our lives for decades.
We know the monolith. The monolith is a single, chubby, messy, sometimes even cute functional brick. This architectural style is the king of “putting all your eggs in one basket”. Oftentimes born accidentally, monoliths might be easier to comprehend (after all, all there is lies just there in front of you) but can still be difficult to deal with because refactoring them requires extensive modifications across their code base: you move one variable here and the whole thing comes down crashing. Monoliths tend to be fertile ground for anti-patterns (global variables being the classic) and showcase plenty of static allocation with little to no memory management. On the upside, monoliths are easier to manage, debug, and analyze (of course we all know exceptions). Still, should a monolith crash, you just bring the whole thing back up, like a drunk who falls from their chair, and off you go. If you made your monolith stateful enough, getting the chubby guy back to work may take quite a short time. This is an underappreciated advantage of monoliths1; we too often ignore failover when we do software, or how to act when the thing crashes. Because it’s not IF, but WHEN it will crash. Why it wouldn’t crash? All, absolutely ALL software eventually crashes.
On the other side, the service-based structural style decomposes an application as a collection of loosely coupled, self-contained, fine-grained "services", whereby a service could be a process or a thread—definitions vary—all communicating through certain protocols. One of its theoretical goals is the evergreen “separation of concerns”, but also it’s claimed that SBAs allow teams to develop and deploy their services independently of others. These benefits come at a cost to maintaining such decoupling; interfaces need to be designed carefully and treated as well-documented APIs.
But here’s the catch (there’s always a catch): the SBA approach crumbles as complexity and stakes grow: when an application is composed of a myriad of components, availability and reliability concerns obviously surface because managing the failover of all services become a task in itself.
For instance, let’s base our analysis on a known, revered example of an SBA: the 5G core network. In a 5G core, different services are assigned different roles (called Network Functions), such as mobility handling, session management, policy handling, and user plane data ingress and egress handling.
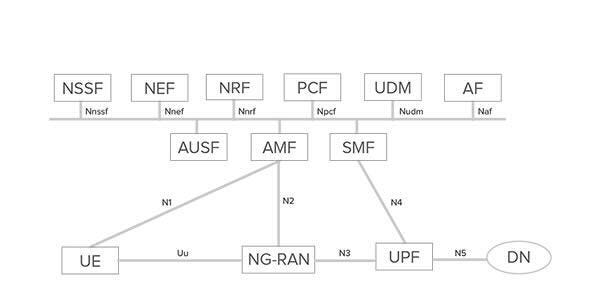
As with most SBAs, the 5G core is nowhere and everywhere at the same time. Not a single service is the 5GC, although all of them are. Of course, if everything works; a core becomes a core if all services are working as expected. Side note: I find it quite amusing to see something distributed being called a “core”.
Now, while observing the figure above, one thought that quickly comes to mind is: where is the reliability and availability of the 5G core handled? As in, who guarantees the services are working as expected and in case of failure of a network function (NF), there will be a respawning or restart executed? Who ensures state will be kept when a service pushes up daisies? There is no service at sight called “failover management”, or similar.
5G core services are just software: either threads or processes (containerized or not) running on top of a computing environment, whether virtual or bare metal. Therefore, they may (and will) crash. If a 5GC UPF network function dies like a coward, the user data flow will stop. Shortly: if you were watching Netflix, now you won’t. Who's in charge of bringing back a crashed UPF and bringing it back keeping the right configuration so the data session will not be interrupted?
When you start digging around, you see that all the roads lead to pushing the problem of availability and reliability of SBAs under the DevOps rug, that is, leaving the problem to be a mere “orchestration” problem. Of course, the DevOps guys will love the challenge and jump into it without hesitating, creating along the way a lot of complexity combined with a non-negligible amount of vendor lock-in with their affectionate approach to dependencies and cloud-native things. Nothing wrong with the DevOps crew, they’re doing their job. However, service-based architectures need to be designed with availability and reliability built-in. Reliability and availability can’t be vendor-specific. Shell scripts or K8s can’t be your lifeline, as those tools are generic and largely unaware of the specific needs of your architecture. More importantly, reliability is never something you can add later.
The lovely dilemma about reliability and software monoliths: if they crash, the whole thing crashes. But if they crash, they’re easier to recover because the whole thing crashes.