
Systems' Autoimmune Diseases
When I was around 15 years old, I built my first electronics experiment following an article in an electronics magazine. It was a rudimentary “blinky” of sorts, composed of the good-old 555 timer chip, a potentiometer to change the blinking frequency, and a driving transistor to turn a LED on and off.
After struggling with several things that were absolute firsts for me such as soldering, wire wrapping, etc, it was finally ready, so I powered it on. I saw the red LED blinking twice or thrice before I noticed a whitish smoke coming out of the 7805 regulator, and I smelled what would end up becoming a familiar smell throughout my professional career: a semiconductor getting fried. I remember being excited, despite the smoky outcome. Was it a victory or a defeat? Well, it depends how you look at it: the system worked; only that it did for a short time. Had an external observer briefly come to see my rudimentary circuitry for those 2-3 seconds when the LED flashed and left, he or she would’ve thought I had nailed it.
On the other side of the spectrum, the Voyager 2 on board computer officially holds the Guiness records for the “longest period of continual operation for a computer”. The redundant Computer Command System (CCS) onboard NASA's iconic deep space probe has been in operation since the spacecraft's launch on 20 August 1977, this means 16,618 days, or 45 years, 5 months, and 29 days of uptime to this date.
My blinky might be a strong contender for the “shortest period of continual operation for a thing”, but I bet there are things that have worked well for even shorter periods of time.
Granted, my experiment had all the odds against it, considering the cold soldered joints, the burned wire wraps, and the loose balls of solder roaming around the place.
The systems we design and manufacture follow a similar score: they tend to work for a while; the key lies in the time windows we pick to assess their performance. If we choose an infinitesimally small sampling window, most systems ever made have done perfectly fine. But is that time window aligned to what we expected? Bit of a different story. I wouldn't have minded having my experiment working for a longer time just to show it off a bit to my friends.
In fact, we are describing nothing revolutionary here, but reliability. From the dictionary, reliability is described as “the probability that a product, system, or service will perform its intended function adequately for a specified period of time”. The shorter the time span, the highest the probability the thing can be considered functional. The longer the period of time, the more likely the bitter realization that nothing lasts forever.
My overall impression after reading classic reliability theory is that, when applied for designing highly coupled architectures, it seems to miss the bigger point. Mainly because it tends to strictly focus on “component” reliability in an isolated manner. Yes, books do cover the “system” reliability with the usual series/parallel topologies analysis of black boxes but still the probability of failure of each box in most of those books depends on itself; the failure is intra-component. And it also expects we will always have the MTBFs, FITs, or whatever numbers of the components at hand, which is seldom the case.
But systemic reliability also depends on the interaction between a subsystem to its neighboring subsystems and vice versa, including cross-coupling factors and qualitative methods.
A useful view is to think of networks, services and the risk and implications of potential “deniability of service” from one or more elements in the architecture. The thesis is: a system is a big network of networks, and each and every node in that collection of networks provides a certain service, which can be interrupted either permanently (the thing is damaged forever) or non-permanently (a glitch or an interruption due to unknown reasons). A network, when observed with a coarse lens, can be seen as a “system” which also provides a service, only that if you peek inside that network there could be other networks providing a service for that “parent” network to provide its own service.
For instance, a PCB board can be thought of as a network, although it is a component with a “systemic” entity on its own. In fact, a PCB is undoubtedly a network of components hooked up together, following a certain topology the designer chose. Moreover, a PCB is also a network of networks because they might use for example Systems-on-Chips (SoC) which are internally complex interconnections of elements. See for example the internal composition of a SoC (Zynq Ultrascale+ from Xilinx1) (also note the diagram is greatly simplified):
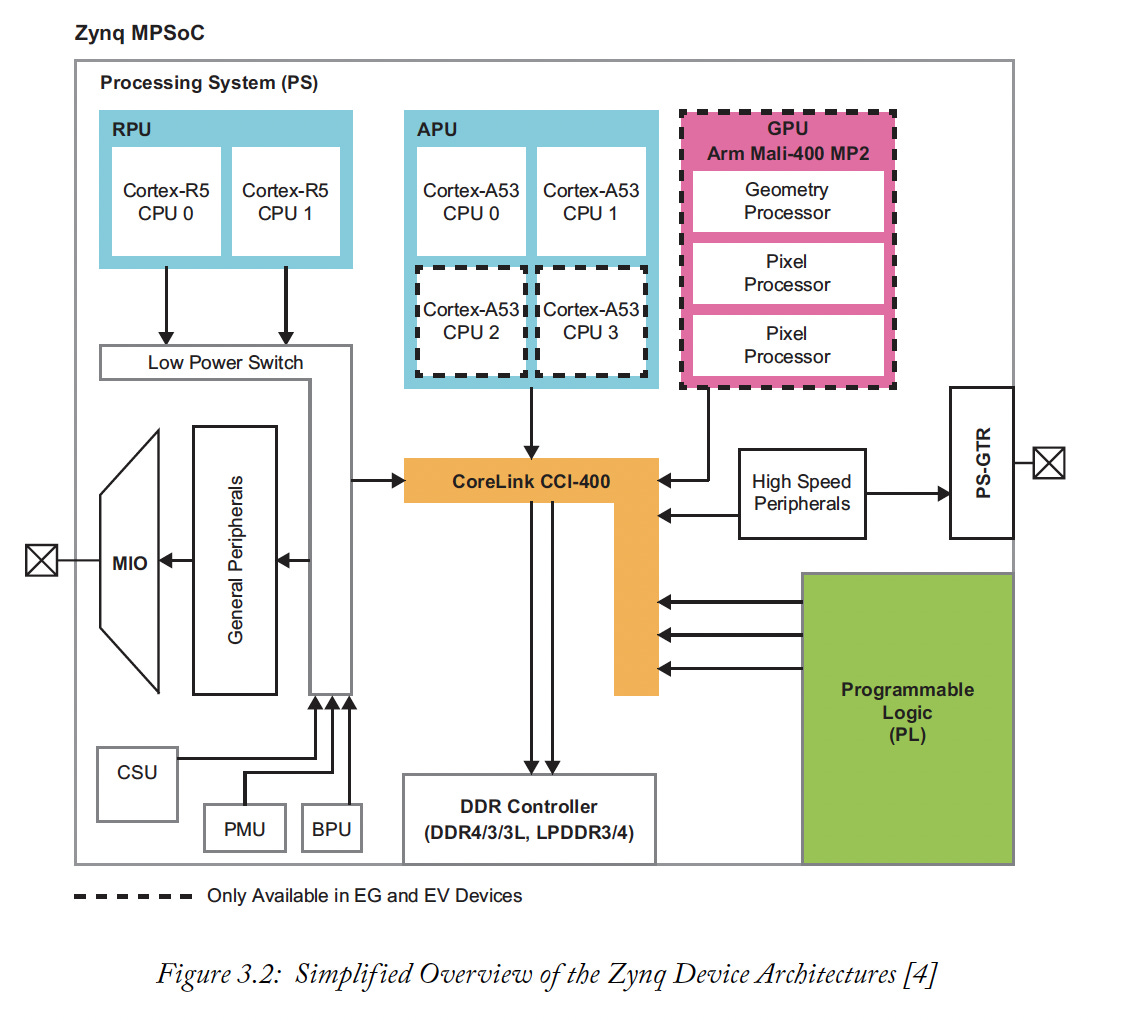
Granted, SoCs and PCB boards are kind of “fixed” networks, in the sense that rerouting the flow of services between its nodes is not so straightforward because things are glued to the boards, tracks are etched, and all the stuff is soldered together.
Now, using some graph theory, we can model our system architectures as a hierarchical composition of networks made of nodes and edges, putting some effort in identifying what services nodes provide and assess the implications of nodes being unable (momentarily or permanently) to provide its service. And of course, setting a limit in terms of granularity so we do not go down to the atomic level or quarks providing a service to protons2.
The graph-based approach can be a way to overcome the blindness subsystem suppliers may cause on us in terms of reliability if we happen to be “horizontally integrated” (what a silly term). Suppliers will most likely not provide a schematic diagram of their things nor a single-numbered, quantitative probability of failure3, but if we request them provide a simple acyclic, rough graph depicting the topology of their products (just how things are interconnected and what kind of function or service they provide, with bubbles and lines) they would not be revealing anything really proprietary, and we could then input this into a general network model and assess things like eigenvector centrality (how influential a node is in the network), degree centrality (how well connected it is), betweenness centrality (how “in the middle” it is; i.e., how huge of a single point of failure it is), alternative paths, etc.
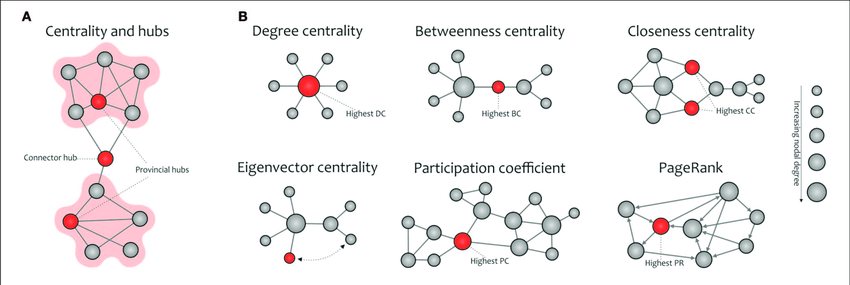
Complex systems can suffer “autoimmune” denial-of-services, where internal parts of it may prevent neighboring components from providing their functions—for the detriment of the whole—although the affected components might working perfectly well in absence of the offending interaction. Electromagnetic interference, conducted noise, mechanical vibrations, and more importantly human errors4, are potential “killers” of an otherwise healthy system, and all independent from the bathtub curve. The key is to design to always provide alternative paths in the network in light of problems what will happen. Because they will.
Restricting the discussion of system reliability to strict component failure and numerical probabilities is not enough. Reliability and availability are richer concepts which must also include potential deniability of function due to the cross-interaction of the elements of its internal network. Autoimmune failure is a thing.
The single most difficult challenge in modeling is to know where to stop adding detail
And even if they do, the issue about these quantitative values is that they might reflect probabilities “as designed” and not “as built”.
Approximately 80 percent of airplane accidents are due to human error (pilots, air traffic controllers, mechanics, etc.). Think of the “betweenness centrality” of some of these actors in the air transportation system